Ген вам
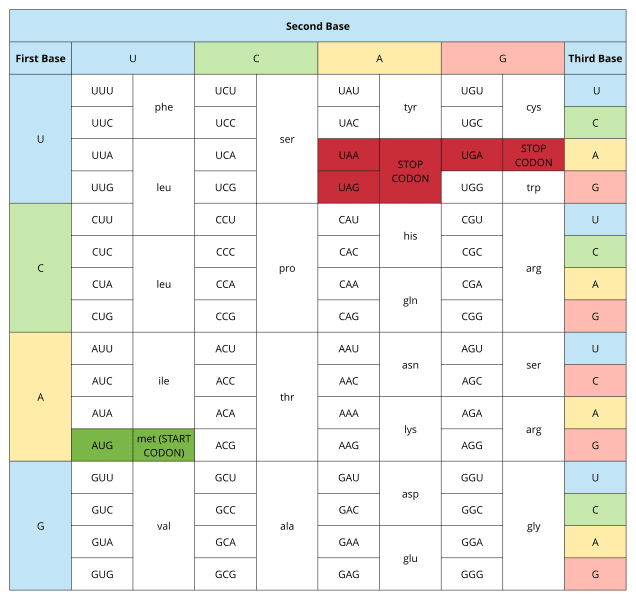
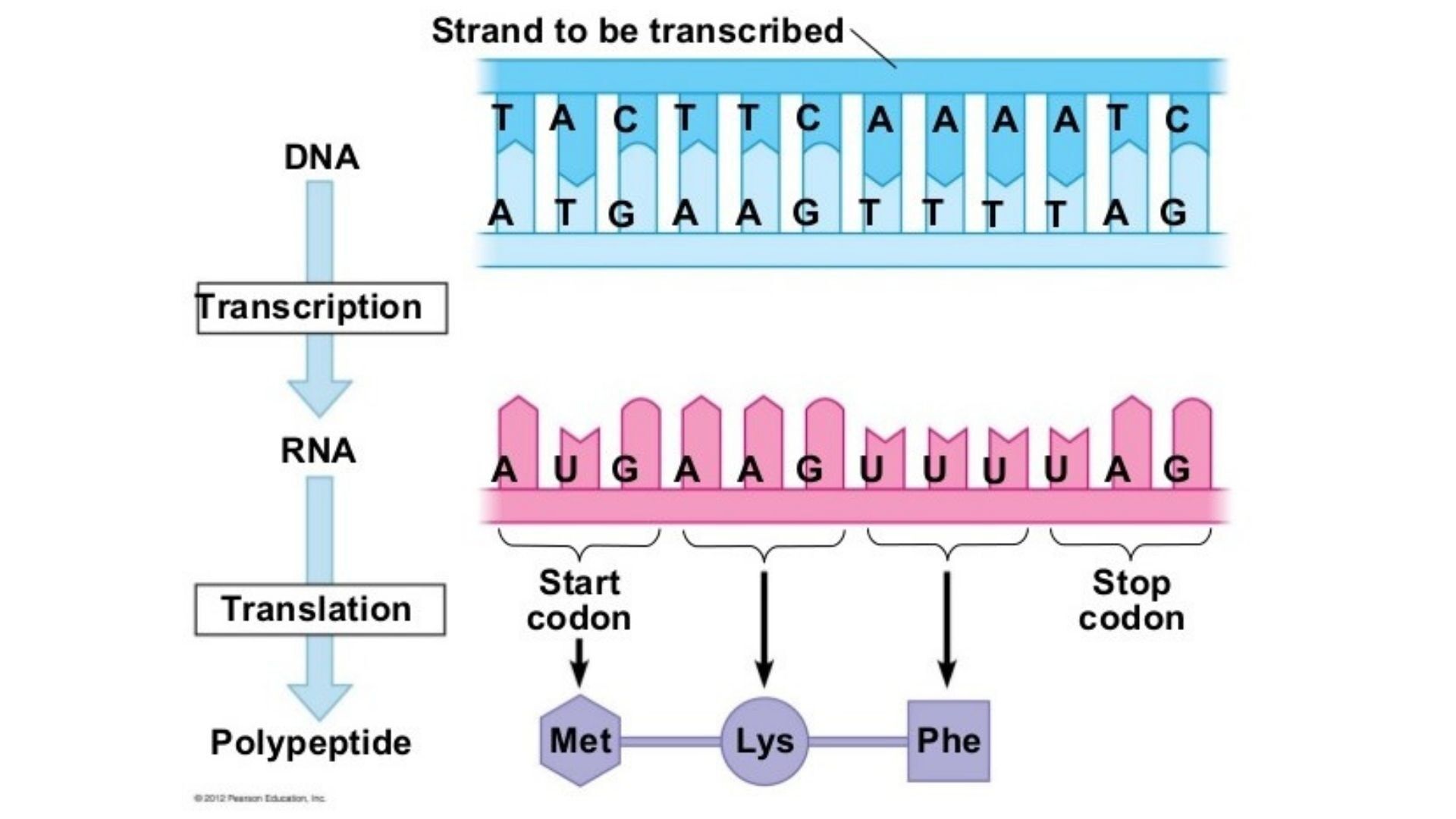
Aug. 20th, 2025 12:01 pmОбщепринятого словаря генов пока нет, но существуют базы данных, откуда можно извлечь формулу нужного протеина. Вот к примеру скрипт на Питоне, показывающий структуру инсулина. Не забудьте поставить ваш email.
Запускаем:from Bio import Entrez, SeqIO
from Bio.SeqFeature import SeqFeature, FeatureLocation
# Set email for Entrez (NCBI requirement)
Entrez.email = "your.email@example.com" # Replace with your email
def fetch_codon_sequence(accession, gene_name):
try:
# Fetch the GenBank record
handle = Entrez.efetch(db="nucleotide", id=accession, rettype="gb", retmode="text")
record = SeqIO.read(handle, "genbank")
handle.close()
# Find the coding sequence (CDS) for the specified gene
for feature in record.features:
if feature.type == "CDS" and "gene" in feature.qualifiers:
if feature.qualifiers["gene"][0].lower() == gene_name.lower():
# Extract the coding sequence
codon_sequence = feature.extract(record.seq)
# Translate to verify it matches the protein
protein_sequence = codon_sequence.translate(to_stop=True)
return {
"accession": accession,
"gene": gene_name,
"codon_sequence": str(codon_sequence),
"protein_sequence": str(protein_sequence)
}
return {"error": f"No CDS found for gene {gene_name} in accession {accession}"}
except Exception as e:
return {"error": f"Failed to fetch sequence: {str(e)}"}
# Example: Fetch codon sequence for human insulin (INS gene)
accession_id = "NM_000207" # GenBank accession for human insulin mRNA
gene_name = "INS"
result = fetch_codon_sequence(accession_id, gene_name)
# Print results
if "error" in result:
print(result["error"])
else:
print(f"Accession: {result['accession']}")
print(f"Gene: {result['gene']}")
print(f"Codon Sequence: {result['codon_sequence']}")
print(f"Protein Sequence: {result['protein_sequence']}")
$ python3 fetch_codon_sequence.py
Accession: NM_000207
Gene: INS
Codon Sequence: ATGGCCCTGTGGATGCGCCTCCTGCCCCTGCTGGCGCTGCTGGCCCTCTGGGGACCTGACCCAGCCGCAGCCTTTGTGAACCAACACCTGTGCGGCTCACACCTGGTGGAAGCTCTCTACCTAGTGTGCGGGGAACGAGGCTTCTTCTACACACCCAAGACCCGCCGGGAGGCAGAGGACCTGCAGGTGGGGCAGGTGGAGCTGGGCGGGGGCCCTGGTGCAGGCAGCCTGCAGCCCTTGGCCCTGGAGGGGTCCCTGCAGAAGCGTGGCATTGTGGAACAATGCTGTACCAGCATCTGCTCCCTCTACCAGCTGGAGAACTACTGCAACTAG
Protein Sequence: MALWMRLLPLLALLALWGPDPAAAFVNQHLCGSHLVEALYLVCGERGFFYTPKTRREAEDLQVGQVELGGGPGAGSLQPLALEGSLQKRGIVEQCCTSICSLYQLENYCN